もう半年前になってしまいますが、3月に行われたYAPC::Okinawa 2018 ONNASONについて。
yapcjapan.org
本イベントについては、すでに2本の記事を書きましたが、
YAPC::Okinawa 2018 ONNASONの記録 - the code to rock
ノンプログラマーのプログラミング活用法 - the code to rock
まだもう1本分、これも書いておかないと・・と思っていたトピックがいくつかあったので、少し時間ができたこのタイミングで一気に書いておきたいと思います。
目次
前夜祭
まずは本番前日の前夜祭。国際通りに面したビルの5階、結婚式の2次会などもできそうなステキ・スペースで開催されました。
当日の様子はこの辺りから。
30d.jp
この前夜祭、リジェクトコン*1とその後のLTから構成されていて、ぼくは翌日の本編で発表する予定だったので、この日はただボーッと見ているだけのお客さんとして参加するつもりだったのですが、会場に着いてみると思っていた以上に知らない人が多い・・時々、Perl入学式つながりで知っている人や、過去のYAPCでお会いした人とは挨拶できましたが、でもやっぱり基本、知らない人ばかり。
んー、これ、このままじー・・っと2時間ぐらいチビチビお酒を飲みながらここで過ごすの、ちょっとつらいかも・・? と思い、急遽ホテルまでMacを取りに戻って、LTに参加させてもらうことにしました。
LTに参加することで、自分が誰なのか、少なからぬ人に周知できると思ったし、時間を持て余すこともなくなるし、と。
しかし、この中途半端な野心がその後のスタッフの皆さんの仕事を増やすことになってしまい・・。というのも、いざLTとなって接続を始めたらなかなかモニターにスライドが反映されない。押しても引いてもまったく駄目。それも、順番が最後から2番めぐらいだったので会場の皆さんは注目しているし、うわー、ミスった、すみません! もうやめます! ゴメンナサイ、じゃあ次の方! とか泣きそうになりながらその場で撤退宣言をくり返していたのですが、現場を仕切っていた  id:codehex さんをはじめスタッフの皆さんが「いや、大丈夫ですよ」と優しく&粘り強くセッティングを手伝ってくれて、最後には
id:codehex さんをはじめスタッフの皆さんが「いや、大丈夫ですよ」と優しく&粘り強くセッティングを手伝ってくれて、最後には  id:karupanerura さんが「これでどうだ」とセットしてくれたのが届いてようやくスタート。
id:karupanerura さんが「これでどうだ」とセットしてくれたのが届いてようやくスタート。
いやあ・・本当に皆さんの胆力というか、タフさ、落ち着き、頼りがい、どれを取っても見習いたいです・・ありがとうございました。とくに codehex さんの「大丈夫ですっ」には救われました。
後から思いましたが、ぼくが翌日の本編で、そこそこリラックスして、緊張しすぎずに発表できたのは、この前夜祭でもうこれ以上ないぐらいのテンパりを体験したからだと思っています。いくら何が起きるかわからない本編だとしても、上記以上の失敗というか、焦った雰囲気はもうナイだろう、と思ったので。実際、本編の方でもスタッフの皆さんにたくさん助けて頂いて、まったく滞りなく進めることができました。
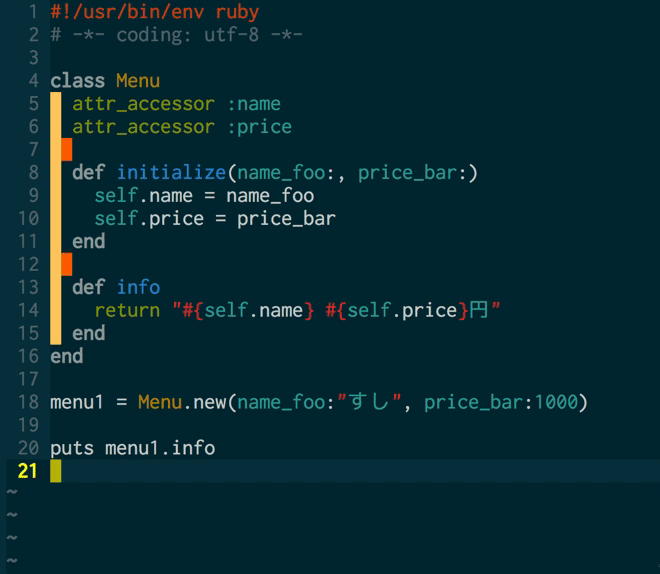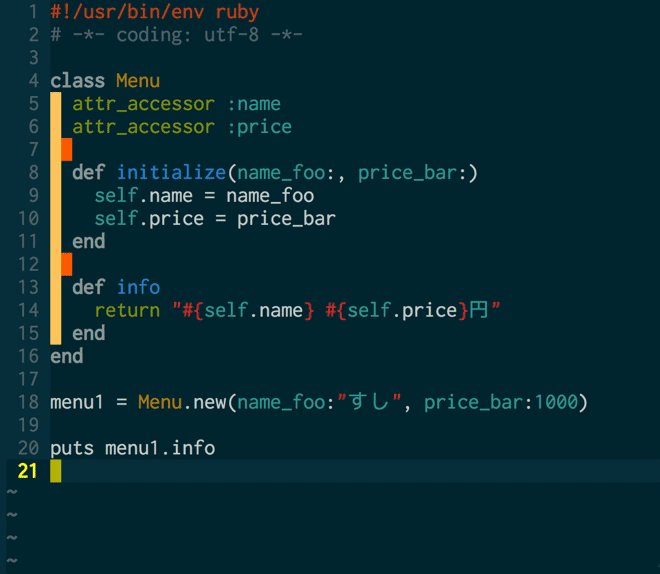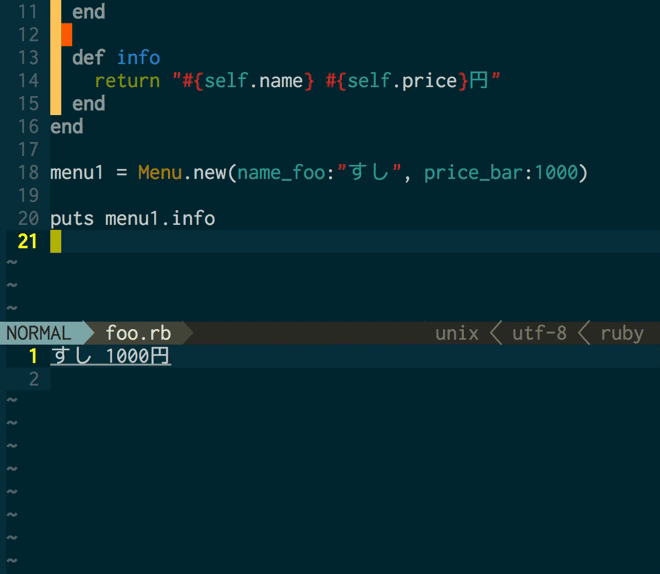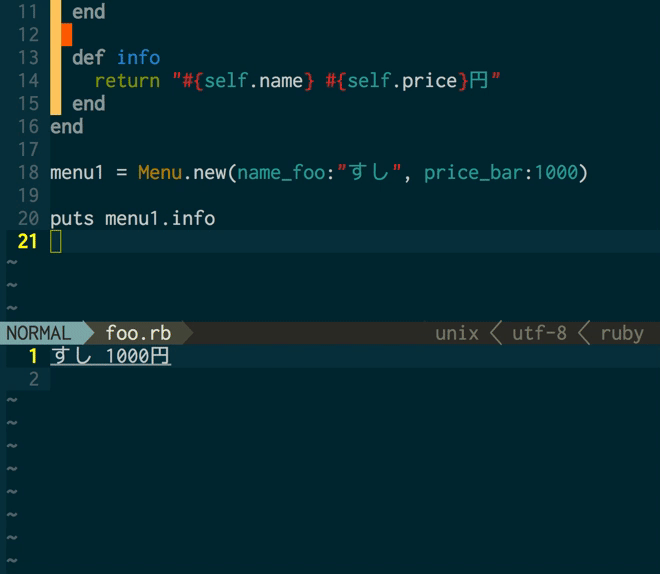
さて、そんな経緯で行ったLTですが、ぼくがその会場で何かしら見るに足る、価値と言えるものを提供できるとしたら、とりあえず自動文字起こしの実演ぐらいかな・・と思ってそれをやりました*2。実際には、そのようにして起こした文字をVimからtextlintを呼び出して自動校正する、というところまでやりたかったのですが、これはtextlintが動かない・・というのを2〜3回繰り返したところで時間切れ。
まあ、文字起こしの方ではけっこう良い反応を頂いて、最後の時間切れのところでも「ああ〜、残念〜!」という雰囲気を会場で一体になって醸せた感じもするので、自分としてはOKというか、充分な成果だったかなと思っています。
ちなみに、そのときにtextlintでやりたかったのはこんな感じのことでした。(当日使う予定だったテキストで再現)
youtu.be
このワーッと滝のように流れていくのが、純粋に面白いなって。それを最後に見てもらったら最初のドタバタもチャラにできるかな・・と思っていましたが、そうも行かなかったのが自分らしいなと思っております。*3
あらためまして、当日サポートしてくださったスタッフの皆さん、そして声を上げて反応してくれた会場の皆さん、ありがとうございました。
当日(私信)
その翌日、本編の出来事に関しては上記2本のブログでだいぶ書いていますが、これまでに書きそびれたことをひとつだけ。というのは、じつはぼくの発表会場では、以前にPerl入学式のサポーターとしてご活躍&サポーターチャットの方でも時々やり取りしていた  id:gomayumax さんが部屋付きのスタッフ業をされていて、でもぼくは初対面だったのでそれがgomaさんだとは結局最後まで気づかなかったんですよね〜・・。まったくまともな挨拶もせず、失礼しました・・😅また次の機会に。
id:gomayumax さんが部屋付きのスタッフ業をされていて、でもぼくは初対面だったのでそれがgomaさんだとは結局最後まで気づかなかったんですよね〜・・。まったくまともな挨拶もせず、失礼しました・・😅また次の機会に。
そのさらに翌日、3/4にはPerlハッカーの@skajiさんの呼びかけで、以下のハッカソンが催されました。
connpass.com
ぼくはもちろん(というか)こういった会にはこれまで縁がなかったのですが、今回はスピーカーでしたし、エイヤという感じで申し込みまして、参加してきました。
前日の本編後の懇親会(というか飲み会)にけっこう遅くまで出ていたので、この日は二日酔いがけっこうキツかったですね・・。
しかしその懇親会で、「いやー、明日ハッカンソン行くんですけど、やることなくて・・とりあえず雰囲気だけ味わいに行きます」みたいなことを言っていたら、 @charsbarさんから「そんなこと言わないで〜。何かできることあるんじゃないの?」とニコニコしながら突っ込まれてしまい、んー、たしかに。何かあるかなあ・・できること・・と考えていましたが、とりあえず編集者を名乗ってはいるので、じゃあPerl関連のドキュメントでも何かしら見て回って、直せそうなところがあれば手を入れてみるか・・と。
それで、会場に着いてからさっそくperldoc.jpを見に行って、何かできることはあるかな・・とひとしきり周遊。
japan.perlassociation.org
ハッカソン会場にもいらしていた @charsbar さんから、修正依頼を送るならどうするのか、などもその場で教えてもらって*4、しかしこれ、実際に何かやるとなると、ただ頭から見ていくより自分の使っているモジュールなどから見た方がいいか・・とか、けっこう砂漠に水をまくような大変さを実感。
ということで、これはこれとして見るとして、他に何かないものか・・と思っているところで、ふと、少し前に目にしたJPAさん(Japan Perl Association)のWebサイトで、部分的に情報が古かったりリンク切れになったりしているところがあったのを思い出したので、そちらの修正作業をやることに。
幸い、ハッカソン会場にはJPA理事の@karupaneruraさんもいらしていたので、さっそくその旨相談。数秒で「じゃあ、この時間だけ編集権限を渡しますよ」と決定、すぐにアカウント手続き、1分後にはもうページの編集ができる状態になっていました。すご・・。
あまりのスピード感に眩暈を覚えつつ、ざくざく作業。まずは修正対象になりそうなページや箇所をリストアップ。
要修正の箇所と、要検討につき修正案を提案するまでにする項目に分けていきます。
その後は要修正のところからどんどん修正。終わったら修正内容を簡単にGistにまとめて @karupanerura さんに共有。というあたりまで行ったところで、終了30分前ぐらい。あっという間!&なにこの充実感!
タイポやリンク切れの箇所についてはここで示してもあまり意味がないので、わかりやすい成果をひとつだけ。
以下の、Perlの参考文献を示したページで『初めてのPerl』と『続・初めてのPerl』のリンク先が古い版だったので、最新版に差し替え。
japan.perlassociation.org
その他、参考書籍として深沢千尋さんの『かんたんPerl』と木本裕紀さんの『業務に役立つPerl』も追加してはどうか? と提案しておきました。
ゆるくて鋭い突っ込みと具体的なレクチャーで作業を促してくださった@charsbarさん、前夜祭に続き圧倒的なパフォーマンスで段取りを組んでくださった@karupaneruraさん、そしてこのような機会を作ってくださった@skajiさん、ありがとうございました。
焼肉
エンジニアといえば焼肉ですが、この日の打ち上げ(?)も焼肉でした。たしか会場は以下。
焼肉酒場 牛恋 那覇松山店(那覇/焼肉) - ぐるなび
入ってすぐ、店員さんから「牛恋(うしこい)は初めてですか!?」と前のめりに聞かれて(たぶん決まり文句)、「あ、はい・・」という感じになったのが記憶に深く残っています。
参加者は錚々たる面々。上記の方々に加え、本編の最後にキーノートを務められた@yappoさん、同じくPerl Mongerとして著名な@xaicronさん、そしてもう何年も前、YAPC::Asiaのリジェクトコンのときに「malaさんですか?」と話しかけて以来のmalaさん等々。
とにかくハイレベルなプログラマーが集まっているので何を話しているのか理解できない時間の方が長かった気がしますが、まさにそういった時間を体験することこそがこのハッカソンに参加した目的でもあったわけで、考えてみるとその念願はこの焼肉会でようやく達成されたのかもしれません。
個人的には、@xaicronさんに以下の記事およびそれを含むテスト系のアドベントカレンダーがすごい参考になって何度も見直している、という話をできたこと、そしてそれを書いた頃にはどういう動機でどんな感じで書いていたのか、みたいなことをお聞きできたのは嬉しかったですね。
perl-users.jp
ちなみに、Perlアドベントカレンダーのテストの話といえば、@myfinderさんの以下もそれはもう何度も読んでいます。
Test::Moreでテスト事始め - JPerl Advent Calendar 2009
お土産屋めぐり
最終日。3/3が本編だったので、翌3/4に沖縄を発った人も多かったようですが、ぼくは上記のハッカソンに参加したので帰りはこの日、3/5でした。
結果的には、このスケジュールがYAPC恒例の飛行機ガチャにつながって、出発時刻は延期につぐ延期、もう今日はダメか・・? という頃になってようやく&突然飛んで、しかし羽田に着いた頃にはもう終電が自宅まで届いてなくて、たしか蒲田あたりに一泊するはめになったりしましたね・・。
しかしそこから少しだけ時計を巻き戻して、飛行機の予定は夕方だったので、ひとまず午前および昼過ぎまではようやくの&今回初の沖縄観光。
といっても、それほど時間があるわけでもないので、とりあえず那覇の公設市場で本場の沖縄そばを食べて、残った時間でお土産を買って帰ろう、という算段でした。
沖縄そばをどこで食べるか? については、さとなおさんこと佐藤尚之さんの以下を参考にしました。
沖縄の行った店リスト(170店)|さとなおのおいしいスペシャル
さとなおさんはぼくがかつて震災ボランティアを手伝っているときに、団体は違ったもののそのご活躍を見ながら、「ああ、すごい人だな」と思っていた方。信頼のおける、尊敬できる人。その人が沖縄のあちこちを食べ歩いて、ちょうどぼくが今回歩き回れる範囲も上のページでいろいろレポート(&レート付け)してくれています。ありがたい!
ということで、まずは目当てにしていた公設市場から。1階には生鮮食品のお店がすごい勢いで営業を繰り広げていますが、その2階には飲食店街が広がっています。そこをぐるりと一周した後、さとなおさんのレポートを読みながら「ここがいいかな」と思ったところに入店・・したつもりが、いきなり失敗。じつはこの飲食店街、店同士がびっしり並んでいるのですが、その店の境界が非常にわかりづらい。それで、目当てにしていた店に入ったつもりが、隣の店の席に着いて注文してしまいました。

(絵に描いたような普通の沖縄そば)
いや、普通に全然おいしそうだし、実際「こんな感じだと思ってた」という味だったし、値段も量もほとんど隣と変わらないので、不満ということではないものの、それでもいきなりつまづいた〜・・という感じ。
幸い、このときには半量で頼んでいました。かなりレアな機会ということもあり、そば一杯で終わるつもりはなかったので・・。それで、ふたたびさとなおさんのレポートを見ながらあちこち歩いてみたところ・・出会ったお店がこちら、「牧志そば」。

ちょっと見づらいですが、ドアに「ソーキそば専門店」と謳っています(肉筆で)。そしてさっきの店よりずっと安い。さらには(たしか)100円追加で沖縄名物の炊き込みご飯「じゅーしー」も食べられる。ということでそれらを注文。

(目が覚めるほどシンプルなソーキそば)

(じゅーしー。普通にボリュームある)
んー、おいしい!(ガッツポーズ)
やっぱりさっきの市場のお店、悪くはなかったけど、いわゆる観光客向けの感じだったのかな・・と思ってしまうほどこちらの店は大満足。諦めなくてよかった・・。
気を良くして、しばらく散歩。

(パラソル通り、と言うらしい)

(でかい)

(ぐっと来る)

(猫)

(ちんすこうはここで。@国際通り)
こんな感じでグルグル回ってから、ふたたび公設市場に戻ってきたところでなんだか気になるお店を発見。たぶんこちら。
www.satoukibikotobuki.com
さとうきびジュース・・。ここで飲まなかったら後悔しそう、と思っておそるおそる注文。すると、いきなりナタみたいなものでバシン、バシン、とご主人がさとうきびをタテに割り始めて、おもむろに鉛筆削りみたいなジューサーに投入。これ、すごいな・・と思って許可を取って撮らせて頂きました。
youtu.be
(マシンの下の方にコップがセットされていて、そこにジュースが入る感じみたい)
できあがり。

そのまま店内の小机を借りて飲み干しました(持ち歩いたらゴミの処分に悩みそうだったので)。けっこうスッキリした甘さでおいしかったです。
そろそろこの辺で疲れてきたので、お土産探しモードに切り替え。先ほど、公設市場の食堂階で1枚のチラシを見かけて、「ゆっくる」という観光案内所が紹介されていたので、とりあえずそこへ向かいます。
machigwa.info
アーケード街の並びにある小さなスペースですが、スタッフさんたちがいろいろ優しく教えてくれました。この辺でお土産屋は・・? と聞くと、すぐ近くにある「てんぶす那覇」というビルの1階に、この案内所の姉妹店のような感じで「ショップなは」という店が入ってるので、そこに行ってみたら、とのこと。
ショップなは
このてんぶす那覇、ものすごい穴場スポット。1階には休憩できるスペースもあるし、トイレも観光案内所もある。国際通り近辺というのは、なにげに「ちょっと休める場所」というのがないので、これはすごい助かりました。ということで、お土産を探す前にしばらく休憩・・。
の後、お土産物色。店員さんにあれこれと相談。「こういうのありますか?」「こういうのは?」と。家族へのお土産はもちろん、個人的にはなんと言っても古酒。「古酒ってあまり馴染みがないんですが、どういうのがオススメでしょう?」と聞いて、教えてもらったのがこちら。
www.koosugura.jp
たしか30度で720cc。1800円前後。初めてだったらこれがオススメ、と。折しもキャンペーン的なタイミングで、寝かせる前のそれ(いわゆる泡盛)も小瓶でついてくるという。嬉しい!&即決。
トータルでたぶん20分ぐらい、あーでもないこーでもない、とじっくり選んで、ようやく会計。そして自宅への郵送もお願いしました。
とにかく先ほどのまちぐゎー案内所「ゆっくる」にしても、この「ショップなは」にしても、まったく何も知らない状態で那覇情報を知りたかったら最適の場所だと思いました。
とくに「ゆっくる」の方では「沖縄そばめぐり」のマップなどももらって、うわー、今さら! 最初にここに来ればよかった・・と激しく後悔しましたね・・。まずはこちらの案内所を訪ねて、全体を把握してから各所をめぐれば効率が良かったなあ、と思いました。というか、次行くことがあったらそうします。
飛行機ガチャ
上にも少し書きましたが、YAPC名物の飛行機ガチャも体験できました。この日は夕方ぐらいから雨が降り出して、一気に豪雨になり、しかし東京はさらにすごかったらしくて「羽田に着陸できないから」という理由でなかなか飛べなかったようです。
個人的には、その那覇の豪雨が地味にキツくて、靴も靴下もビショ濡れ・・替えの靴下は預けた荷物に入れてしまっていて、売店で靴下、いやせめてビーチサンダルでもないかと探しましたがそういうのも無く・・。けっこう心身ともにダメージを受けました。
そんな中、ヤケになって買った紅いもソフト。少しはストレスも軽減された気がします。

結局、飛行機は21時過ぎぐらいに那覇を飛び発ち、しかし自宅までは間に合わなかったので都内で一泊して、3/6に帰り着きました。
おつかれ!!
終わりに
ということで、記録しそびれていたあれこれをまとめて書いてみました。これで思い残すこともなく、ぼくのYAPC::Okinawaを終わらせることができます。(おそい)
三度、精神的にも肉体的にもタフなスタッフの皆さん、そして誰も彼もめっちゃ優しくてすぐに友達みたいになってしまった沖縄の皆さん、楽しい旅をありがとうございました! また行きたい!!
















")
")