Scrapbox、最近はほとんど毎日使っています。日記的に使うことが多いですが、メールやブログの下書きに使うことも多いです。
いろんなことがScrapbox周りで効率化している気がするので、現在の使い方について記録しておきたいと思います。
目次
家族との情報共有
他人と使うケースとしては、最近では家族との情報共有で利用することが多いです。家族とは基本的にはチャットでやり取りしていますが、たとえば買物リストとか、旅行の持ち物リストや旅券に関わる各種の情報(予約番号とか)のように、何度も見直したり、チャットで流れないでほしかったりするデータはWikiのような静的な場所を使った方が良いので、そういう用途で使います。
ちなみに、以前はこれをサイボウズLiveでやっていました(が、すでに同サービスは終了)。最近Kibelaを使ってみたところ、フイフイ動くしかわいいし、家族との用途ならKibelaもいい気がしましたが(たしか5人ぐらいまでは無料だし)、非営利でプライベート用途のための料金プランをより切実に想定しているのは、Scrapboxの方かなという気もします。それに、家族はMarkdown記法にこだわったりもしないですからね・・。
仕事関連でも時々使いますが(フリーランス・ユーザーなので無料プラン)、これはたぶん本来の用途に比べてちょっと特殊で、ほとんど更新しているのはぼくだけ、というパターンが多いですね。自分が頭の中だけで覚えておくのはちょっと大変だな、というネタを入れておいたりします。ただいずれにしても、現時点では仕事での使用頻度はそれほど多くありません。
メールやブログの下書き
個人用途で言うと、最初にも書いたようにメールやブログの下書きでよく使います。と言っても、ちょっとした内容なら、そもそも下書きなんてしないわけですが、けっこう大事なメールとか、込み入った内容の場合には、ぼくは3段階ぐらいに分けてそれを書くので、そういうときに役立ちます。
第1段階では一気にラフを書き切ります。この時はサクッと手元で起動できるVimを使うことが多いですが、いずれにせよディテールや整合性などは気にせず、とにかく頭にある情報を出し切ることが優先です。
それが終わったらScrapboxにコピペして、一旦そこから離れます。いわゆる「寝かせる」状態。
しばらくしたら、その第1段階で作ったものをScrapbox上で直していきます。これが文章を作る上では一番大事な工程です。
もし分量が多く、PCを使えるならVimに持っていくこともありますが、「修正」という点に重きを置くならばやはりScrapboxが有効です。
なぜなら、Scrapboxには「編集画面」がないからですね。編集するための画面が、すなわちそのまま「閲覧画面」になっています。
これ、本当に革命的にすごいことです。Googleドキュメントもそうじゃないか、と思われるかもしれないですが、Googleドキュメントをモバイルから操作しようとすると、編集画面に移動するためにエンピツアイコンをクリックしなければいけません。そして、Scrapboxにはそれがありません。
その話からもわかるとおり、この第2工程の修正作業では、ぼくはPCとモバイルを行ったり来たりします。文章を書く際、というより直す際に、「この表現、変だな」とか「ここタイポじゃん」とか気づきやすいのはどういう時かというと、それは「無責任な人」になったときです。よくTwitterで的外れなリプライをしている人がいますが、そのぐらい無責任な態度で文章を読むと、見方がものすごく厳しく、かつシンプルになり、「こんな言い方じゃわからないでしょ(このオレ様が)」といった具合に様々な指摘が頭の中に浮かんできます。
このような「無責任な人」になるスイッチというか、トリガーになるのが、たとえば上記のような「時間を置く(寝かせる)こと」だったり、あるいは「環境を変えること」だったりします。
そして、その「環境を変える」方法の中でもとくに手っ取り早いのが、「PCとモバイルを行ったり来たりする」ことです。
ぼくの場合、あまり寝かせてる時間がないようなときは、PCで書いた文章をすぐに手元のiPhoneで読んだり、iPhoneで書いた内容をPCで見直したりします。そうすると、だいぶ見え方が新鮮になって、変な言い回しやわかりづらい表現に気づきやすくなります。別人のような目で読み返すことができます。
見つけた間違いを修正するときも、Scrapboxに文章を入れておくと、たとえば今までPCで書いたり読んだりしていた文章を、iPhoneのSafariから、新鮮な目のまま(間違いに気づいたときのイメージを保持したまま)修正していくことができます。Scrapboxでは閲覧画面から編集画面に移動する時間が存在しないので、画面遷移の際に微妙なニュアンスを忘れてしまうようなこともなく、感覚的にサッサと直していくことができます。
このような感じで、ちょっと込み入った文章を直すときにはScrapboxをよく使っています。
ターミナルやVimからページを生成
Scrapboxでは、URLにあたる文字列を操作することで、任意のページを自在に生成することができます。
詳しくは以下で説明されていますが、
この機能を利用して、当日または任意の日付の日記ページをターミナルからさくっと生成したり、Vimで書いた文章を少ない手数で新規ページにコピペしたりできるようにしています。
ターミナルから日記ページを作る
まず、ターミナルからどのような操作をしているか紹介します。
ぼくは.bashrcに以下のような関数を入れています。
おそらくプロの人から見れば冗長で、恥ずかしい気もしますが、やりたいことは充分に実現してくれます。
論より証拠ということで、この最後にあるエイリアス「sddn」を使って、ぼくの公開Scrapboxであるところの「https://scrapbox.io/note103/」に本日付(2018/08/31)の日記ページを作ってみましょう。
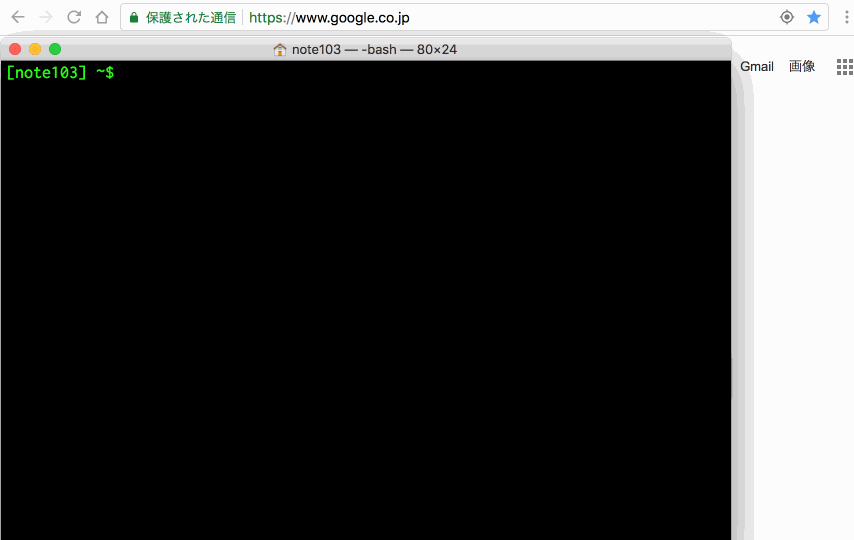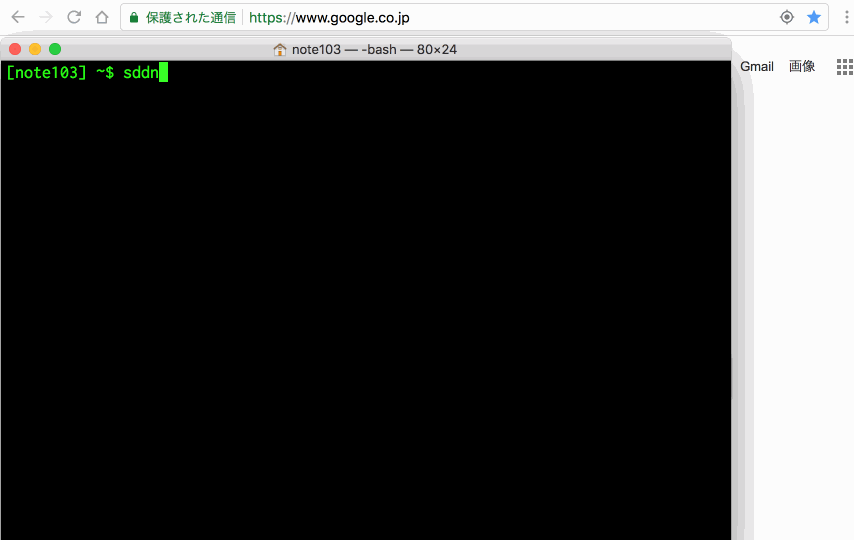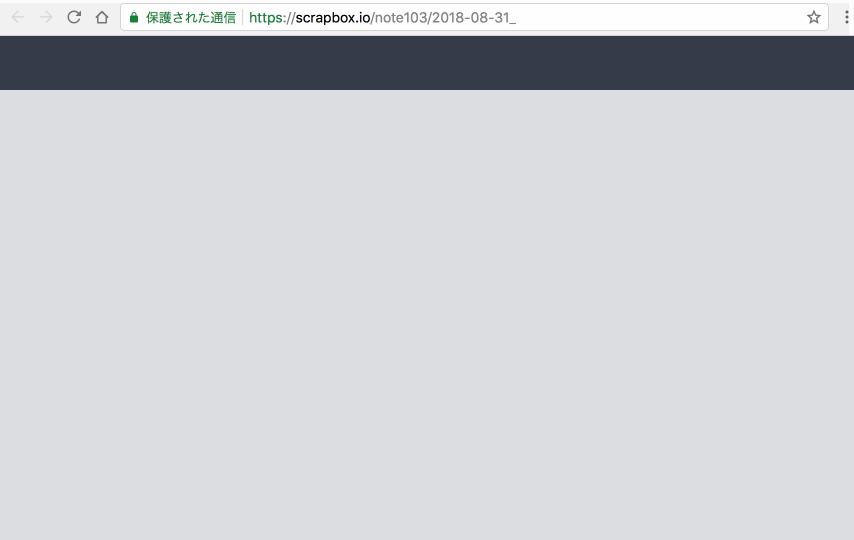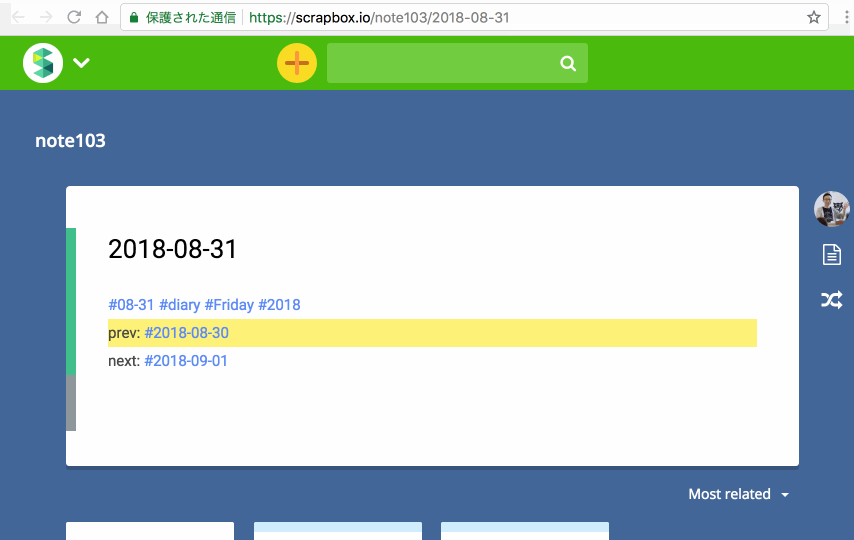
できましたね。個人的には、前後の日付(8/30と9/1)が入るようにしているところがポイントです。
コードの中で、言語設定を英語にしたり日本語にしたりしていますが(L7, 33)、これは曜日を英語にするための処理なので、ターミナルの設定によっては不要かもしれません。
(ぼくの環境では、これがないと「#Friday」のところが「#金曜日」になります)
また、openコマンドを使っているので、Mac以外のOSだとそのままは使えないと思います。
if文の中の処理は、当日の日記ではない、任意の日付のページを作りたいときのためのものです。
例として、「2016/01/01」の日記を作ってみましょう。
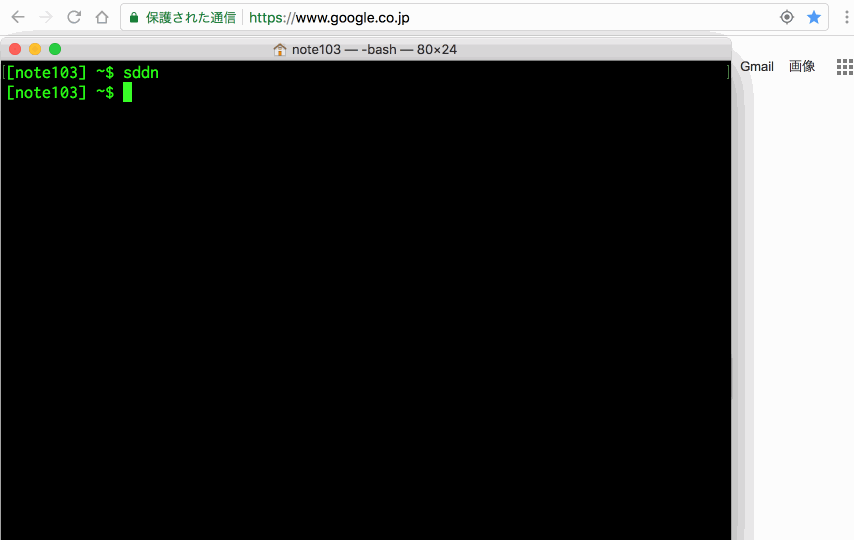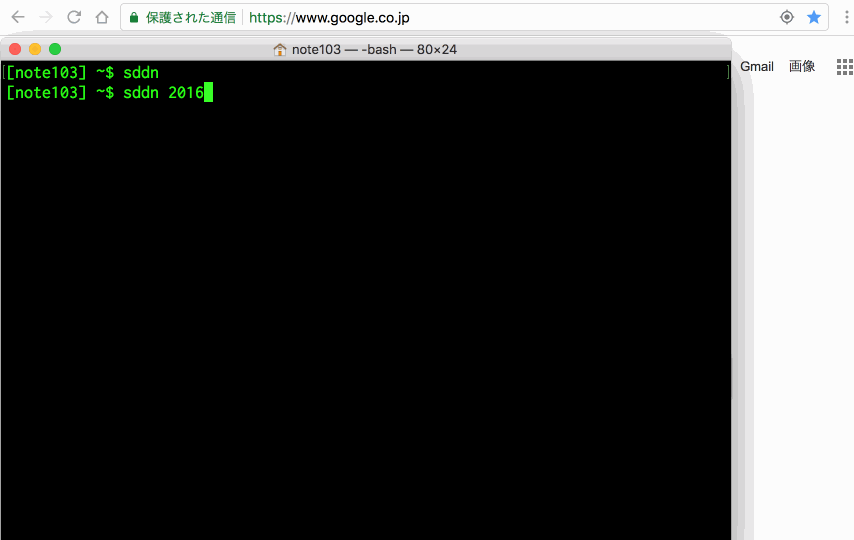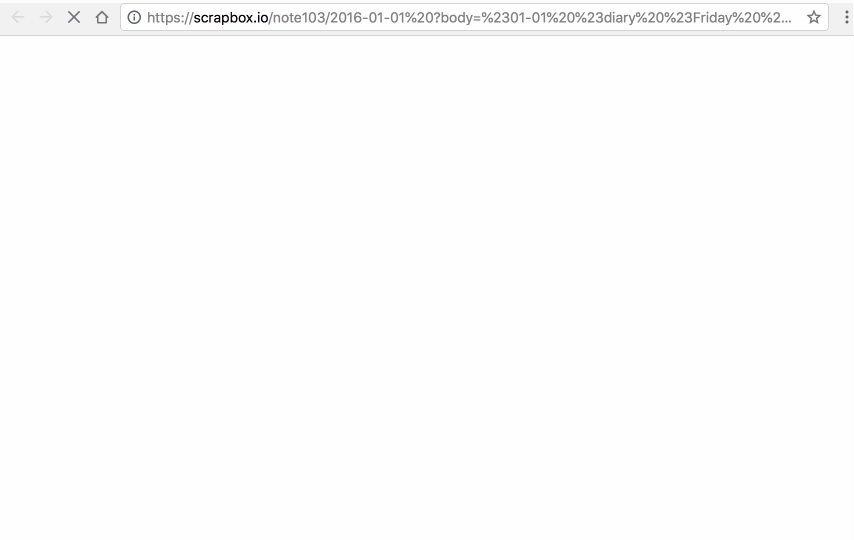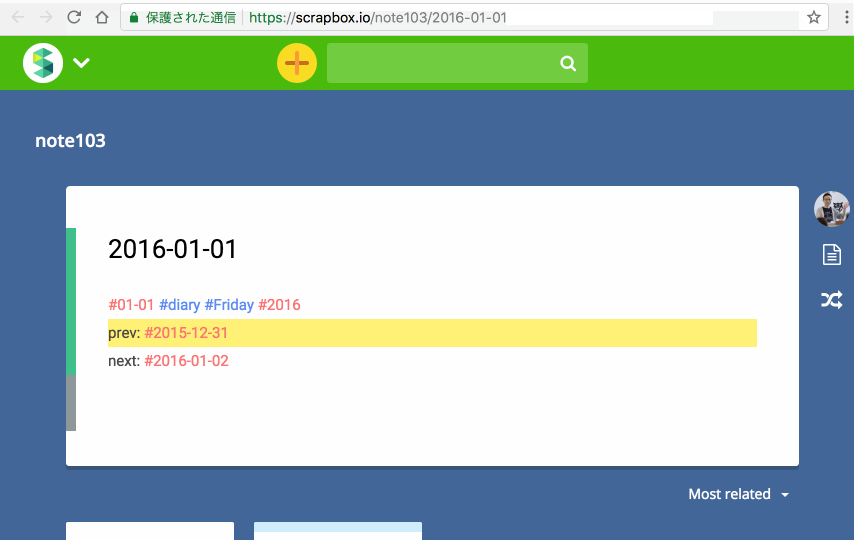
できました。ちなみに、この本文の内容は、上記のヘルプにもありますが、中身を全部URLに入れ込むことにより生成しています。
また、エイリアスの設定からもわかりますが、「sddn」というコマンドの実体は「sbdd」という関数にプロジェクト名の「note103」という引数を渡しているだけです。よって、その引数を変えればどのようなプロジェクトにも応用できます。
なお、このようにいろいろデフォルト情報(前後の日付や各種タグなど)が詰まった新規ページではなく、当日または任意の日付の日記にアクセスしたいだけ、というときには、以下の関数を利用しています。
function sbd { local site="$1" if [ -z "$site" ]; then return; fi local ymd=$(date +%Y-%m-%d) if [ ! -z "$2" ]; then ymd="$2" fi open "https://scrapbox.io/$site/$ymd" } alias sdn="sbd note103"
たとえば、すでにその日の日記を作成済みの状態で、さっきの日記ページ作成コマンドを使うと、初期設定用のタグや前後の日付がまた入ってしまうので、単にその日記を閲覧したいだけであれば、これを使うのがシンプルです。
Vimから新規ページを作ってコピペする
もう一つ、時々使うのが「いまVimで書いてる文章をそのままScrapboxにコピペする」というワザです。前半で触れた、Vimで書いたメールのドラフトをScrapboxに持っていくときなどによく使います。
先にコードを示しておくと、.vimrcに以下の関数およびマッピングを書いておきます。
では、動かしてみましょう。

はい。GIF動画だと順番がわかりづらいですが、
1)最初に2行だけ文が入ったVimがあって、
2)ファイル下部のコマンドラインで対話型の操作をすると、
3)一意の日時から生成されたScrapboxの新規ページが現れて(この時点では新規ページはカラ)、
4)そこにクリップボード上にコピーされていたテキスト情報をペースト。
5)で、最後に少し内容が変わった最初のVimが出てきています。
この最後の段階でわかりますが、上記2)と3)の間で元ファイルの1行目に目的地のURLが追加されています。それを使って、Vimプラグインの「open-browser.vim」でジャンプすると自動的にページが生成される、という仕組みです。
なお、Vimでヤンク(コピー)したテキストは、デフォルトではMacのクリップボードには入らないので、これについては別途設定が必要になります。
ぼくの場合は、以下のような設定が.vimrcに入っていました。(これを書きながら久しぶりに思い出しました)*1
" Use clipboard register. if has('clipboard') if has('unnamedplus') set clipboard& clipboard+=unnamedplus else set clipboard& clipboard+=unnamed endif endif
この方法の良いところは、新規ページを作成しても、中身が自動的にリンク先にペーストされないことです。
え、自動で反映されたほうが便利じゃないの? と思われるかもしれませんが、Vimで書いている内容ってけっこうセンシティブなものが多いので、万が一ペースト先のプロジェクトが間違っていたら大変なことになります。(いわゆる誤爆)
その点、この方法だとまずは新規ページが作成されるだけで、それまでVimで書いていた中身は、まだクリップボードに保持している状態なので、行き先のプロジェクトが目当てのものであることをきちんと確認してから、安心してペーストすることができます。
・・といっても、じつはそれはあくまで結果論で、初めは自動的にペーストできるものを作ろうとしていたのですが、URLに中身を持たせる方法だと文章量に制限があるようで、長文には向かなそうだったので、結果的にこの方法に落ち着いています。


")
")